Pada artikel tentang Data Mining dan Java sudah dijelaskan tentang metode machine learning, yaitu supervised dan unsupervised learning. Pada artikel ini akan dibahas sekilas tentang metode ketiga bernama reinforcement learning (RL). Pada RL agent berkomunikasi dengan lingkungannya tanpa dibantu oleh tutor atau guru untuk pembelajarannya. Tujuan RL adalah menemukan policy di mana memilih sebuah aksi pada suatu step-time yang mengantarkannya untuk mendapatkan reward terbaik dari lingkungannya. Setiap aksi yang agent lakukan, lingkungannya merespon dengan sebuah reward yang menunjukkan efektifitas aksi di setiap step-time. Pada aksi yang dilakukan agent tidak menganut benar atau tidaknya aksi yang dilakukan.
RL adalah sub area machine learning yang menitikberatkan kepada cara sebuah agent mengambil aksi di lingkungannya. Di sini agent melakukan maksimalisasi pemikiran tentang reward untuk jangka panjang. RL diinspirasi dari fenomena biologi dan mengelola pengetahuan melalui eksplorasi aktif terhadap lingkungannya. Pada setiap langkah, RL memilih beberapa aksi yang mungkin dilakukan dan menerima reward dari lingkungan atas aksi spesifik yang dilakukannya. Aksi terbaik yang harus dilakukan di beberapa state tidak pernah diketahui sehingga agent harus mencoba beberapa aksi-aksi dan urutan-urutan aksi yang berbeda serta belajar dari pengalamannnya.
RL biasanya dideskripsikan sebagai Markov Decission Process (MDP) yang terdiri dati sebuah agent, set state yang mungkin S, set aksi-aksi yang mungkin A(S) untuk semua state S, dan sebuah fungsi reward R(s,a) yang menentukan reward yang diberi lingkungan atas aksi yang dilakukan agent. Fungsi policy pi mendeskripsikan bagaimana agent belajar pada beberapa time-step t. Policy optimal didefinisikan sebahai pi*. Fungsi value V(s,a) mendefinisikan reward total yang diharapkan ketika melakukan aksi a pada state s jika untuk mencapai state berikutnya diikuti policy optimal pi*. Inilah fungsi di mana agent harus belajar untuk memperoleh policy ini. Ilustrasi RL ditunjukkan pada Gambar 1 berikut ini.
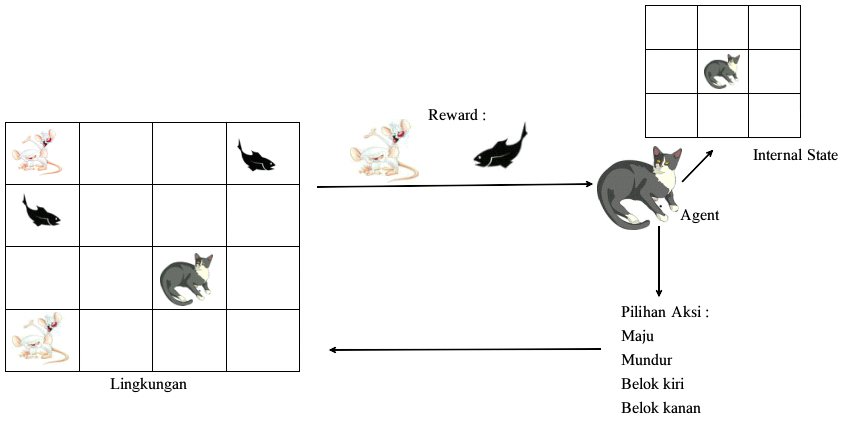
Gambar 1. Ilustrasi Reinforcement Learning
RL sangat cocok untuk masalah-masalah terdistribusi. RL membutuhkan memori dan komputasi yang medium pada setiap node-nya. RL melakukan mekanisme pemeliharaan beberapa kemungkinan aksi-aksi yang berbeda beserta nilainya. RL memerlukan waktu untuk mencapai konvergen. RL mudah diimplementasikan, fleksibel terhadap perubahan topologi, dan mencapai aksi optimum. Contoh implementasi algoritma RL adalah Q-Learning, Dual RL, TPOT Reinforcement Learning, dan Collaborative RL.
Referensi:
[1] Raghavendra V. Kulkarni, Anna Forster, Ganesh Kumar V. “Computational Intelligence in Wireless Sensor Network : A Survey”.